
Приклад парсингу новин з популярного українського порталу ukr.net!
Всім привіт!
В даній статті буде наведений приклад невеличкої функції на мові PHP з використанням бібліотеки Guzzle для парсингу новин з ukr.net.
Маю допущення, що ukr.net займається веб-скрейпінгом (вичитує html сторінки новинних сайтів та використовує їх у своїх цілях…стрічка новин).
І так, розпочнемо.
Крок перший – створюємо папку в якому буде наш проект. У моєму прикладі папка називається news_ukr.net.
Крок другий – встановлюємо Guzzle бібліотеку з використанням composer:
composer require guzzlehttp/guzzle
Для встановлення без composer можете переглянути мануал від самого Guzzle.
Крок третій – створюємо файл *.php в якому буде наш код (index.php).
Першим ділом підключаємо нашу бібліотеку Guzzle:
require './vendor/autoload.php';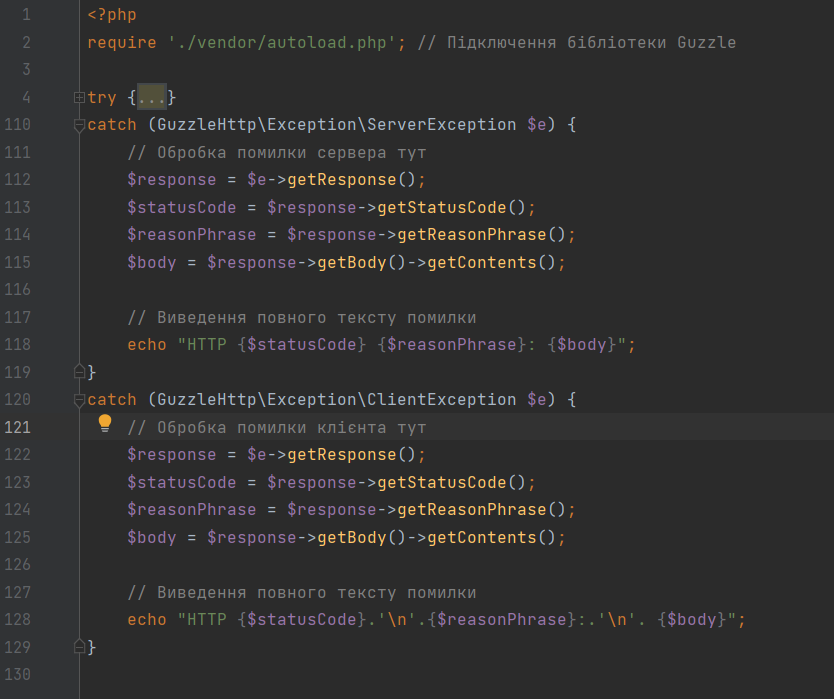
Як ми бачимо, ми використали конструкцію try {} catch {} для відловлення помилок, та виведення повного опису помилки, якщо така станеться.
По власному досвіді можу сказати, що даний механізм, допомагає розібратись в чому ж МИ могли допустити помилку.
Блок try {} буде містити наш код для скрейпінгу новин з ukr.net.
Створюємо функцію, у моєму випадку з назвою generate_clear_pack():
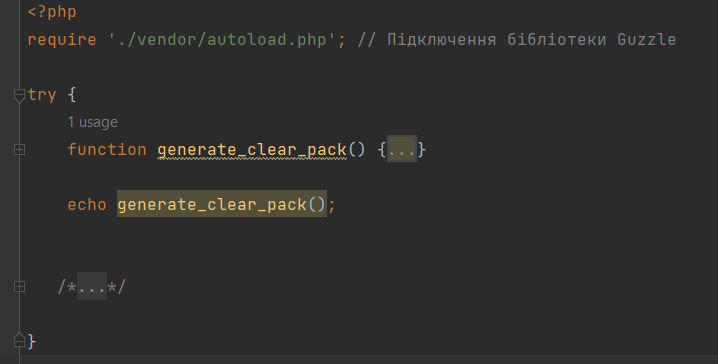
Зразу ж можна викликати нашу функцію командою:
echo generate_clear_pack();Для прикладу ми будемо витягувати новини з укр.нет двох категорії – це «Наука» та «Технології»…все ж наша стаття буде розміщена на освітньому сайті:)
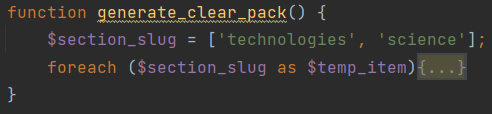
Попередньо дослідивши сайт укр.нет створюємо змінну списка з наступними значеннями:
$section_slug = ['technologies', 'science'];Так як ми хочемо отримати інформацію з двох категорії, нам потрібно створити цикл, який би здійснив пошук всіх новин по категорії 'technologies', а потім по категорії 'science'. Для цього використаємо цикл foreach:
В основному циклі реалізуємо POST запит з допомогою Guzzle клієнтом:

Змінна $search_ukr = $obj->data; – повертатиме масив з масивами, в кожному з яких буде інформація про конкретну новину, її назву, теги, посилання на оригінальний сайт новини.
Кінцевим результатом даної статті ми отримаємо парсер новин з укр.нету які ми будемо записувати в нашу тестову базу даних (якщо Вам лінь створювати базу даних, можете переправити код для запису в json).
Для того, щоб підготовити собі «чистий масив» з потрібною інформацією по новинах створюємо дві змінні пустих масивів та знову оголошуємо цикл:

Вигляд циклу:

Збираємо наш масив з потрібними Нам змінними, а саме:
«id» – унікальне значення новини (буде слугувати нам унікальним id в тестовій таблиці Mysql).
«created_at» – дата створення у форматі datashtamp unix timeshtamp.
«title» – заголовок новини.
«tags» – тег категорії новин, які ми обрали вище.
«title_temp» – назва сайту, з якого укр.нет витягує новину.
«link_original_temp» – посилання на сайт, з якого укр.нет витягує новину.
Масив $pack_masiv[] – являється сховищем конкретної категорії новин в момент виконання коду.
Четвертий крок – створення підключення до нашої попередньо створеної таблички в базі даних Mysql:
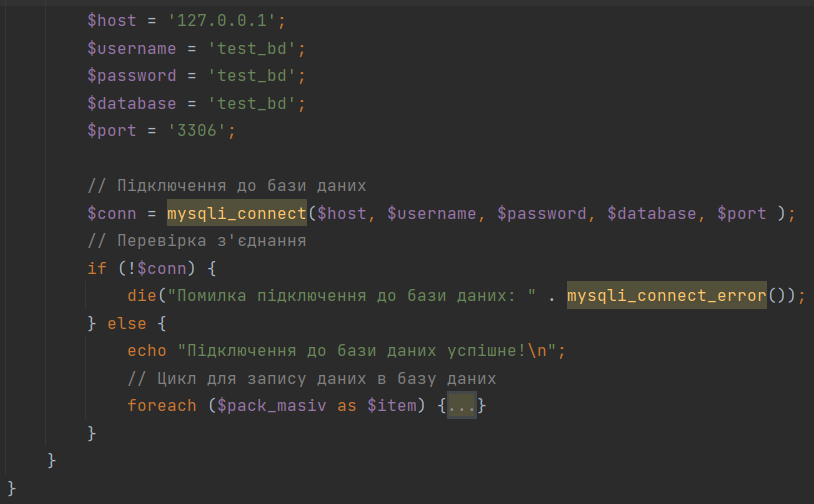
Додаємо перевірку на успішне підключення, якщо підключення до БД успішне – запускаємо знову ж таки цикл для запису інформації в базу даних:

Змінна $sql – містить запит до БД, що створює запис в нашій табличці.
Змінна $check_sql використовується для перевірки, чи існує вже такий рядок в БД. Якщо не існує – виконуємо запит зі змінною $sql.
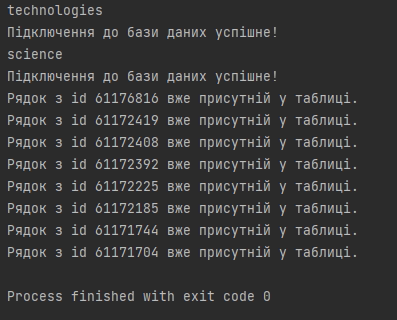
Результат виконання запиту в консолі:
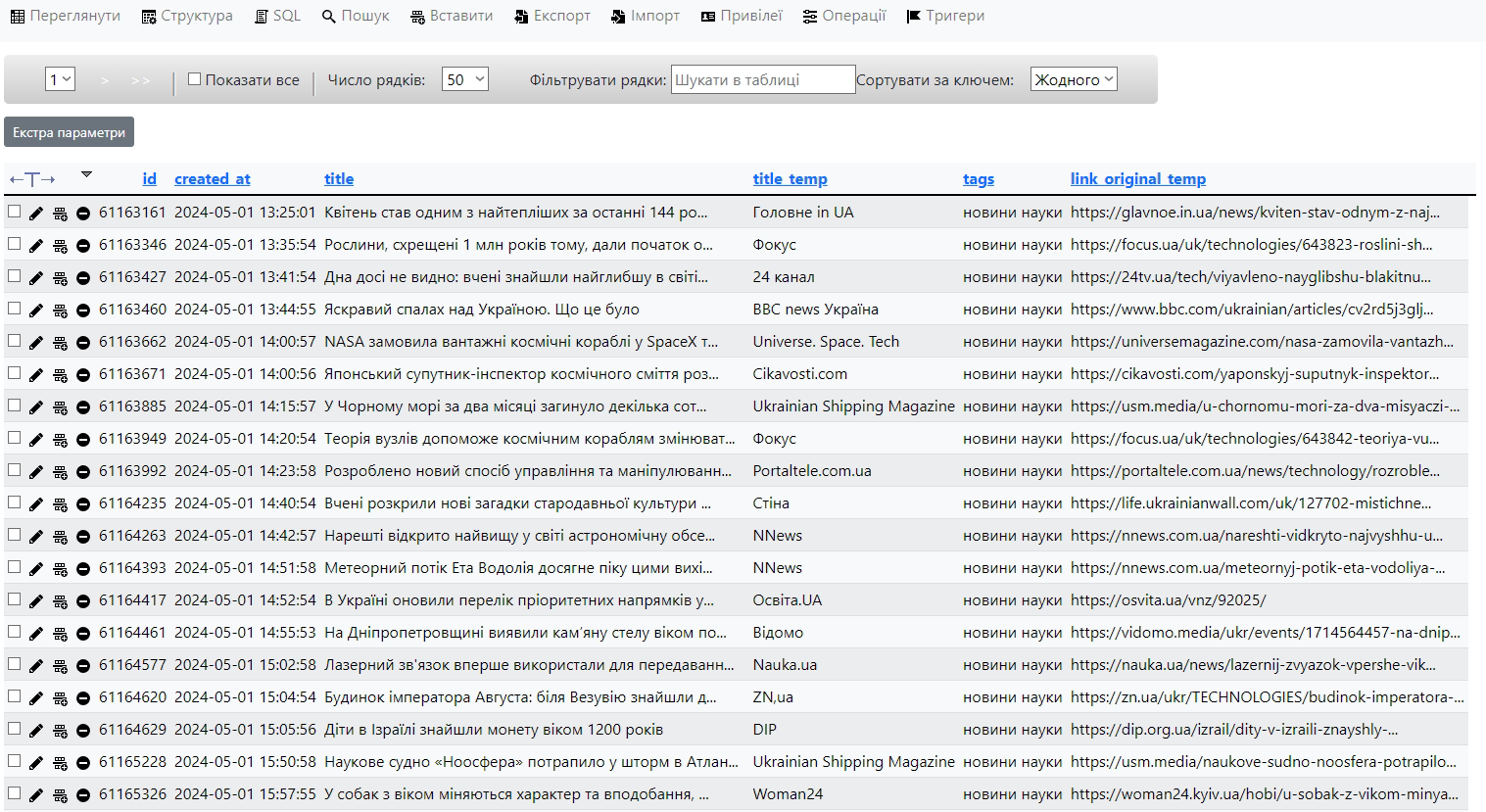
Вигляд записів у тестовій базі даних:
На основі отриманих знань, тепер і ВИ зможете зробити Свій новинний ресурс!)
Буду радий прочитати Ваші фідбеки в коментарях. А можливо нові ідеї для реалізації стартапів.
- 44 перегляди
Коментувати